精确推断
精确推断的实质是一种动态规划算法,它利用图模型所描述的条件独立性来削减计算目标所需的计算量。变量消去法是最直观的精确推断算法,也是构建其他精确推断算法的基础。
精确推断有以下算法:
- 变量消除
- 消息传递
- 团树
近似推断有一下算法:
- 随机模拟
- 马尔可夫链的蒙特卡罗方法
- 变分算法
本文主要主要是针对精确推断算法中的变量消除算法,计算变量的边际分布或条件分布是一个NP难问题,会随着极大团的增长呈指数增长。近似推断是在较低的时间复杂度下,或者原问题的近似解,这种方法更有一般的实用性。
变量消除
有向图
考虑如下的有向图概率图模型,图中共有五个变量:A,B,C,D,E。如果我们假定每个变量有n个值,那么直接的概率描述就是联合概率密度,那么复杂度为$n^5$。如果我们计算$P(E=e)$,那么我们就要计算:
$$P(e)=\sum_{a,b,c,d}P(a,b,c,d,e)$$
可是这个计算过程需要对另外四个变量求和(边际化),那么就需要$n^4$的复杂度。

我们可以将上面的联合概率密度$P(a,b,c,d,e)$进行因式分解:
$$P(e)=\sum_{a,b,c,d}P(a,b,c,d,e)=\sum_{a,b,c,d}P(a)P(b\mid a)P(c\mid b)P(d\mid c)P(e\mid d)$$
假设推断目标是计算边缘概率密度P(e),那么P(c|b),P(d|c),P(e|d)与a无关,将P(a)和P(b|a)的乘积相加。
$$P(e)=\sum_{a,b,c,d}P(a)P(b\mid a)P(c\mid b)P(d\mid c)P(e\mid d)$$ $$=\sum_{b,c,d}P(c\mid b)P(d\mid c)P(e\mid d)\sum_a P(a)P(b\mid a)$$ $$=\sum_{b,c,d}P(c\mid b)P(d\mid c)P(e\mid d)P(b)$$
下面按照b,c,d的顺序进行求和,最后可以得到$P(e)=\sum_d P(e\mid d)P(d)$。使用该方法可以一次减少一个变量。每次只需要执行$O(n^2)$操作,最终复杂度为$O(kn^2)$。
在HMM上进行变量消除
参考[4]中笔记对于该例的介绍,主要是利用当前变量相关变量和非相关的变量进行变量消除,每步消除一个变量,最终复杂度为$O(Tn^2)$,其中T表示变量的个数。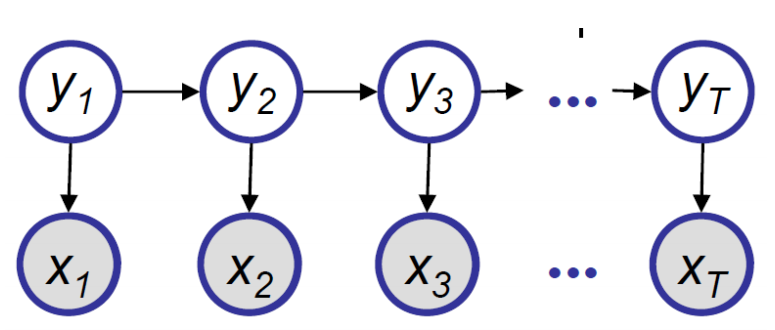
无向图
考虑如下的无向图概率图链模型,总共有五个变量A,B,C,D,E,计算联合概率密度P(e)。
$$ P(e)=\sum_{a,b,c,d}\frac{1}{Z}\phi(a,b)\phi(b,c)\phi(c,d)\phi(d,e)$$
具体计算方法同有向图相似,超级长的公式,不想打,下面用截图来表示。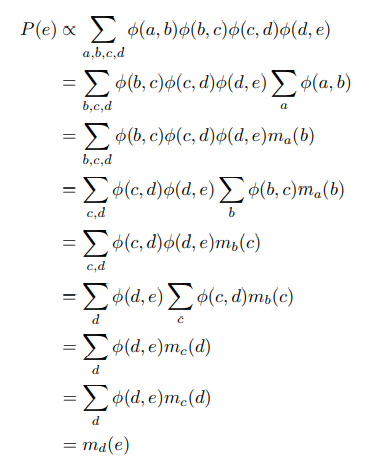
最后通过正则化可以获得最终的概率:
$$P(e)=\frac{m_d(e)}{\sum_e m_d(e)}$$
参考文献
[1] http://www.cs.cmu.edu/~epxing/Class/10708-14/lecture.html
[2] Koller D, Friedman N. Probabilistic graphical models: principles and techniques[M]. MIT press, 2009.
[3] 周志华. 机器学习[M]. 清华大学出版社, 2016.
[4] http://people.eecs.berkeley.edu/~jordan/prelims/?C=N;O=A
注:本文主要参考[1]中第4讲视频以及笔记,参考[2]中第9章,参考[3]中第14章,参考[4]中第3章。
