指数族
将随机变量X写成指数族的形式:
$$p(X=x;\eta)=h(x)exp(\eta^T T(x)-A(\eta))$$
其中:$\eta$是自然参数向量(natural paramater),T(x)是充分统计量(sufficient statistic),$A(\eta)$是对数判分函数(log partition function)。
例子
指数族可以包括许多的例子,比如高斯分布,伯努利分布,多项式分布等。
多元正态分布
令向量$X\in R^k$
$$p(x\mid \mu,\Sigma)=\frac{1}{(2\pi)^{k/2}|\Sigma|^{\frac{1}{2}}}exp \lbrace -\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu) \rbrace$$
$$=\frac{1}{(2\pi)^{k/2}} exp\lbrace -\frac{1}{2} tr(\Sigma^{-1}x x^T) + \mu^T \Sigma^{-1}x^T- \frac{1}{2}\mu^T \Sigma^{-1}\mu - log|\Sigma|\rbrace$$
对应的指数族表示:
$$\eta = [\Sigma^{-1}\mu; -\frac{1}{2}vec(\Sigma^{-1})]$$ $$ T(x)=[x;vec(xx^T)]$$ $$ A(\eta)=\frac{1}{2} \mu^T \Sigma^{-1} \mu + log|\Sigma| $$ $$ h(x)= \frac{1} { {2\pi}^{k/2} } $$
伯努利分布
$$ p(x;\phi) $$ $$ = \phi^x(1-\phi)^{1-x} $$ $$ = exp(log(\phi^x(1-\phi)^{1-x}) $$ $$ = exp(log(\phi^x)+log((1-\phi)^{1-x})) $$ $$ = exp(xlog(\phi) + (1-x)log(1-\phi)) $$ $$ = exp(xlog(\frac{\phi}{1-\phi})+log(1-\phi))$$
对应于指数族:
$$ \eta = log(\frac{\phi}{1-\phi}) $$ $$ T(x) = x $$ $$ A(\eta) = -log(1-\phi) $$ $$ h(x) = 1 $$
其他
很多的分布可以看做是指数族:单变量高斯分布(the univariate Gaussian),泊松分布(Poisson), 多项分布(multinomial),线性回归(linear regression),伊辛模型(Ising model),受限波尔兹曼机机(restricted Boltzmann machines),还有条件随机场(contional random field,CRFs)。
条件随机场
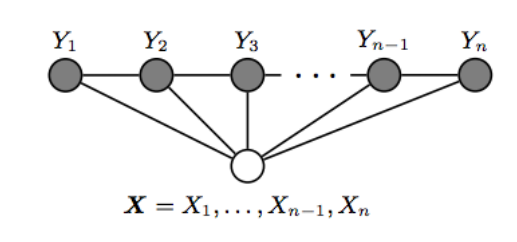
条件随机场是基于上面图的无向图模型,势函数是定义在成对输出上面的。
$$ p_\theta(y\mid x)=\frac{1}{Z(x)}exp(\Sigma_{e\in E,k} \lambda_k f_k(e,y\mid_e, x) + \Sigma_{v\in V,k} \mu_k g_k(v,y\mid_v, x))$$
其中$f_k$和$g_k$是固定的,$g_k$是波尔顶点特征,$f_k$是波尔边特征。
指数族特性
指数族具有如下的特性:
- 对数配分函数的第d阶导数,是充分统计量的第d阶中心距。
比如:对数配分函数的一阶导数是T(X)的均值,其二阶导是T(X)的方差。 - 因为对数配分函数的二阶导是正的,所以对数配分函数是凸的,因此方差总是非负的。
- 我们可以将对数配分函数的一阶导看成自然参数的函数,然后令其为零,反过来利用距参数就可以解决自然参数,记作:$\eta = \psi(\mu)$ 。
- 在指数族上进行最大似然估计与矩匹配是一致的。
- 写出一般指数族的对数似然函数:
$$ const + \eta^T (\Sigma_{i=1}^n T(x_i)) - nA(\eta) $$ - 求似然函数的梯度:
$$ \Sigma_{i=1}^n T(x_i)) - n\Delta_\eta A(\eta) $$ - 令$\Delta_\eta A$为零:
$$ \Delta_\eta A = \frac{1}{n}\Sigma_{i=1}^T T(x_i) \Rightarrow \mu = \frac{1}{n}\Sigma_{i=1}^T T(x_i) \Rightarrow 矩估计=样本距 $$
充分统计量

从贝叶斯的观点出发:如果T具备了我们预测参数$\theta$的所有信息(即T是充分统计量),那么$\theta \perp X \mid T \Rightarrow P(\theta \mid X, T)=P(\theta\mid T)$。
从频率学派的角度出发:如果T已知的用来产生数据的参数,那么$ X \perp \theta \mid T \Rightarrow P(X\mid T;\theta) = P(X\mid T) $
从马尔科夫随机场的角度进行考虑: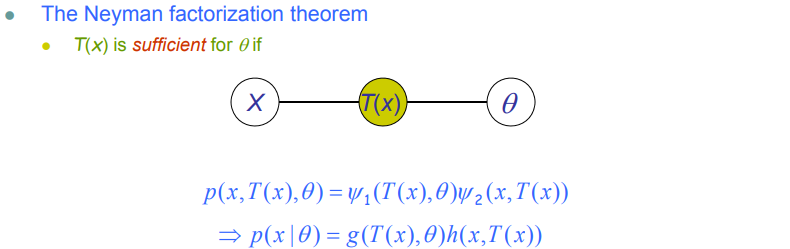
贝叶斯
重新从贝叶斯的角度出发,写出给定自然参数的似然函数,我们选择了一个自然参数先验,然后计算出自然参数的后验概率。
比如:
$$ p(x\mid \eta) \propto exp(\eta^ T T(x) - A(\eta))$$
$$ p(\eta) \propto exp(\xi^T T(\eta) - A(\xi)) $$
$$ p(\eta\mid x, \xi) \propto exp(\eta^T T(x) + \xi^T T(\eta) + A(\eta) + A(\xi)) $$
如果$\eta = T(\eta)$ ,那么后验概率变为:
$$ p(\eta\mid x, \xi) \propto exp(T(\eta)(T(x) + \xi)+ A(\eta) + A(\xi)) $$
当$ \eta = T(\eta)$ ,我们指定$\eta ~exponentialFamily$,这是先验就是共轭先验。
广义线性模型
广义线性模型可以将分类和回归问题进行统一,使用相同的统计框架。
假定:
$$ Y \sim exponentialFamily $$
$$ \eta = \psi(\mu=f(\xi = \theta^T x)) $$
其中Y是响应,x是固定输入,$\theta$是需要学习的参数,$f$(响应函数,response function),$\psi$增加了一定的灵活性,f经常被设定为$\psi^{-1}$(canonical response function)。
广义线性模型的批学习
考虑通过求导的方法来解决最小二乘问题,就是使代价函数达到极小:
$$ J(\theta) = \frac{1}{2} \Sigma_{i=1}^n (x_i^T\theta - y_i)^2 = \frac{1}{2} (X\theta-y) $$
$x_i$表示第i个输入样本,$y_i$表示第i个输出样本。
对$J(\theta)$求一阶导并令其为零,可以得到取得极小值时的$\theta$。
$$ \triangledown J(\theta) = X^T X\theta - X^T y = 0 \Rightarrow \theta^* = (X^T X)^{-1} X^T y $$
使用牛顿法进行迭代寻找最优解,牛顿法更新参数更新准则:
$$ \theta^{t+1} = \theta^t - H^{-1}\triangledown J(\theta) $$
对数似然函数$l = \Sigma_n logh(y_n) + \Sigma_n(\theta^T x_n y_n - A(\eta))$
下面获得Hessian阵:
\begin{equation}\begin{split} H&=\frac{d^2 l}{d\theta d\theta^T}\\
& = \frac{d}{d\theta^T}\Sigma_n(y_n-\mu_n)x_n\\
& = \Sigma_n x_n \frac{d\mu_n}{d\theta^T}\\
& = -\Sigma_n X_n \frac{d\mu_n}{d\eta_n} \frac{d\eta_n}{d\theta^T}\\
& = -\Sigma_n X_n \frac{d\mu_n}{d\eta_n} x_n^T \ 因为\eta_n = \theta^T x_n\\
& = -X^T W X
\end{split}\end{equation}
其中$X = [x_n^T]$,$W = diag[\frac{d\mu_1}{d\eta_1},…,\frac{d\mu_N}{d\eta_N}]$。W可以同过计算$A(\eta)$的二阶导来计算。
代换上式中的$\triangledown J(\theta)$和H,可以得到:
$$ \theta^{t+1} = (X^T W^t X)^{-1} X^T W^t z^t $$
其中$z^t = X\theta^ t + (W^t)^{-1}(y - \mu^t)$。因为W是对角阵,所有该式子具有解耦的作用。
对数几率回归
条件概率分布如下(伯努利分布):
$$ p(y \mid x) = \mu(x)^y (1-\mu(x))^{1-y} $$
其中$\mu$是logistic函数
$$ \mu(x) = \frac{1}{1 + e^{-\eta(x)}} $$
由于$p(y\mid x)$是指数族,
均值:
$$ E[y\mid x] = \mu = \frac{1}{1 + e^{-\eta(x)}} $$
canonical response function:
$$ \eta = \xi = \theta^T x $$
利用上面的方法广义线性模型中的方法求W:
$$ \frac{d\mu}{d\eta} = \mu (1 - \mu) $$
$$ W =
\begin{pmatrix}
\mu_1 (1 - \mu_1)\\
&\ddots \\
& & \mu_N (1-\mu_N) \\
\end{pmatrix}
$$
其中N是训练样本的数量,d是输入样本的维度。上面的方法每代复杂度为$O(Nd^3)$。可以利用拟牛顿法来近似计算Hessian阵来减小运算成本。
共轭梯度每代的复杂度为$O(N d)$,在实际中使用效果更好。dang样本数量较大时,也可以采用随机梯度下降。
线性回归
条件概率分布为:
$$p(y\mid x,\theta,\Sigma)=\frac{1}{(2\pi)^{k/2}\Sigma^{\frac{1}{2}}}exp \lbrace \frac{1}{2}(y-\mu)^T\Sigma^{-1}(y - \mu) \rbrace$$
从上面多元正态分布中,可以写成指数族的形式。
利用上面的方法广义线性模型中的方法求W:
$$ \frac{d\mu}{d\eta} = 1 $$
$$ W = 1 $$
更新规则如下:
$$ \theta^{t+1} = \theta^t + (X^T X)^{-1} X^T(y - \mu^t) $$
总结
- 对于指数族分布,最大似然估计等价于矩估计。
- 广义线性模型是图模型的实际应用中的重要组成部分。
- 要选择合适的独立性以及合适的先验。
参考文献
[1] http://www.cs.cmu.edu/~epxing/Class/10708-14/lecture.html
注:本文主要参考[1]中第6讲视频以及笔记。
