最大似然结构学习
连续型马尔科夫随机场
给定高斯图模型,我们可以用一个伊辛模型来呈现。
$$p(x\mid \mu,\Sigma)=\frac{1}{(2\pi)^{k/2}|\Sigma|^{\frac{1}{2}}}exp \lbrace -\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu) \rbrace$$
下面令$\mu=0$和$Q=\Sigma_{-1}$,高斯模型可以写成:
$$p(x\mid \mu,Q)=\frac{|Q|^{1/2}} {(2\pi)^{k/2}}exp \lbrace -\frac{1}{2}()\Sigma_i q_{ii} (x_i)^2 - \Sigma_{i<j} q_{ij} x_i x_j) \rbrace$$
我们将上式指数中的第一部分看做是定义在节点上的势函数,第二部分是定义在比边上的势函数,也就是说等同于一个伊辛模型。
$$ P(x\mid \Theta) = exp\ (\Sigma_{i\in V} \theta_{ii}^t x_{d,j} + \Sigma_{(i,j)\in E} x_{d,i}x_{d,j} - A(\Theta)) $$
稀疏图模型
协方差矩阵有一个重要的性质是:当$\Sigma_{i,j}=0$有$x_i\perp x_j$;逆协方差矩阵(精确矩阵)的对应的性质为:当$\Sigma_{i,j}^{-1}=0$时$x_i\perp x_j\mid x_{-ij}$。
如果出现$p \gg n$时,得不到最大似然估计,这是我们使用近邻选择得方法,增加惩罚函数来学习稀疏的图模型。
近邻选择可以看做是伊辛模型。
$$ P(x\mid \Theta) = exp\ (\Sigma_{i\in V} \theta_{ii}^t x_{d,j} + \Sigma_{(i,j)\in E} x_{d,i}x_{d,j} - A(\Theta)) $$
最大似然估计
似然条件
有向图中,对数似然可以分解为一组和的形式,每个对应于一个子节点对应其父节点。无向图中,对数似然并不能分解,因为Z是包含了所有的参数的函数。
$$ p(x) = \frac{1}{Z} \prod_{c\in C} \psi_c{x_c}, Z = \Sigma_x \prod_{c\in C} \psi_c(x_c) $$
我们需要通过推测来学习参数。我们获得了输入数据的充分统计量,计数。
$$total\ count:m(x) = \Sigma_n \delta(x, x_n)$$ $$cliqu\ count:m(x_c) = \Sigma_{x_{V\setminus c}} m(x)$$
似然函数为:
$$p(D\mid \theta) = \prod_n \prod_x p(x\mid \theta)^{\delta(x,x_n)}$$
\begin{equation}\begin{split} log\ p(D\mid \theta)&=\Sigma_n \Sigma_x \delta(x,x_n)log\ p(x\mid \theta\\
l & = \Sigma_x m(x)log(\frac{1}{Z}\prod_c \pi_c(x_c))\\
& = \Sigma_c \Sigma_{x_c}m(x_c)log\ \psi_c(x_c) - N log\ Z \\
\end{split}\end{equation}
上式的两个部分对$\psi_c(x_c)$求导:
第一项:
$$ \frac{\partial l_1}{\partial \psi_c(x_c)} = m(x_c)/\psi_c(x_c) $$
第二项:
\begin{equation}\begin{split} \frac{\partial log\ Z}{\partial \psi_c(x_c)} & = \frac{1}{Z} \frac{\partial}{\partial\psi_c(x_c)}(\Sigma_{\tilde{x} } \prod_{d} \psi_d(\tilde x_d))\\
& = \frac{1}{Z} \Sigma_{\tilde{x}}\delta(\tilde x_c, x_c)\frac{\partial}{\partial \psi_c(x_c)}(\prod_{d} \psi_d(\tilde x_d) \\
& = \Sigma_{\tilde x}\delta(\tilde x_c, x_c) \frac{1}{\psi_c(\tilde x_c)} \frac{1}{Z} \prod_d \psi_d(\tilde x_d)\\
& = \frac{1}{\psi_c (x_c)}\Sigma_{\tilde x} \delta(\tilde x_c, x_c) p(\tilde x) \\
& = \frac{x_c}{\psi_c (x_c)}
\end{split}\end{equation}
令导数为零,有:$\frac{\partial l}{\partial \psi_c(x_c)} = \frac{m(x_c)}{\psi_c(x_c)} - N\frac{p(x_c)}{\psi_c(x_c)} = 0$,从结果可以看出,模型的边缘概率密度等于观测的边缘概率密度。
$$ p_{MLE}^{\star} (x_c) = \frac{m(x_c)}{N} = \tilde p(x_c) $$
但是结果并没有给出似然参数的估计方法,只是给出了必须满足的条件。
可分解模型
对于可分解的模型,势函数可以定义于最大团上,团势函数的最大似然等价于经验边际。因此最大似然可以通过检查得到。基于势函数的表示似然$p(x)=\frac{\prod_c \psi_c(x_c)}{\prod_s \psi_s(x_s)}$,其中c是最大团,s是最大团分离的因子。为了计算团势,将他们等同于经验边际。分离因子必须分解为几个邻居,那么$Z=1$。
例一
考虑链$X_1-X_2-X_3$,有团$(x_1, x_2),(x_2, x_3)$,分离因子$x_2$。
$$ \tilde p_{MLE}(x_1, x_2, x_3) = \frac{\tilde p(x_1, x_2)\tilde p(x_2, x_3)}{\tilde p(x_2)} $$
$$ \tilde{\psi}{12}^{MLE}(x_1, x_2) = \tilde p(x_1, x_2) $$
$$ \tilde{\psi}{23}^{MLE}(x_2, x_3) = \frac{\tilde p(x_2, x_3)}{\tilde p(x_2)}= \tilde p(x_2\mid x_3) $$
例二
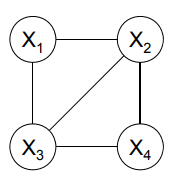
团$(x_1, x_2, x_3),(x_2, x_3, x_4)$,分离因子$x_2,x_3$
$$ \tilde p_{MLE}(x_1, x_2, x_3, x_4) = \frac{\tilde p(x_1, x_2, x_3)\tilde p(x_2, x_3, x_4)}{\tilde p(x_2, x_3)} $$
$$ \tilde{\psi}{123}^{MLE}(x_1, x_2,x_3) = \frac{\tilde p(x_1, x_2, x_3)}{\tilde p(x_2, x_33)}= \tilde p(x_1\mid x_2, x_3) $$
$$ \tilde{\psi}{234}^{MLE}(x_2, x_3, x_4) = \tilde p(x_2, x_3, x_4) $$
不可分离模型-IPF和GIS
如果一个图是不可分离的,也就是说势函数不能以最大团定义,我们不能将经验边际等价于势函数的似然。
Tabular Cique Potentials-IPF
如果团势函数是表格形式或者可以使用简介的参数模型表示,那么我们可以使用IPF来求最大似然估计。
从上面的似然函数导数:
$$\frac{\partial l}{\partial \psi_c(x_c)} = \frac{m(x_c)}{\psi_c(x_c)} - N\frac{p(x_c)}{\psi_c(x_c)} = 0$$
我们可以得到:
$$ \frac{\tilde p(x_c)}{\psi_c(x_c)} = \frac{p(x_c)}{\psi_c(x_c)} $$
因为$\psi_c$隐性的出现了模型边际$p(x_c)$中,所以在点$\psi_c$上存在等式关系,所以直接解出$\psi_c$是非常困难的,因为其出现在了等式两边。
我们将$\psi_c$在右边固定,然后在左边解出,循环所有的团,进行下面的迭代:
$$ \psi_c^{(t+1)}(x_c) = \psi_c^{(t)}(x_c)\frac{\tilde p(x_c)}{p^{(t)}(x_c)} $$
上面的算法可以看做是坐标上升算法,其中的坐标就是势团的参数。因此在每一步中,似然函数的值会增加,这样就可以收敛到全局极大值。这个算法童谣可以被看做是最小化观测数据的分布与模型分布的KL散度(交叉熵),只有当模型是可分解的。
$$ max\ l \Leftrightarrow KL(\tilde p(x)\mid \mid p(x\mid\theta))=\Sigma_x \tilde p(x)log\frac{\tilde p(x)}{p(x\mid \theta)} $$
\begin{equation}\begin{split} KL(q(x_a, x_b)\mid \mid p(x_a, x_b)) &= \Sigma_{x_a, x_b}q(x_a)q(x_b\mid x_a)log\frac{q(x_a)q(x_b\mid x_a)}{p(x_a)p(x_b\mid x_a)}\\
&= \Sigma_{x_a, x_b}q(x_a)q(x_b\mid x_a)log\frac{q(x_a)}{p(x_a)} + \Sigma_{x_a, x_b}q(x_a)q(x_b\mid x_a)log\frac{q(x_b\mid x_a)}{p(x_b\mid x_a)}\\
&= KL(1(x_aq)\mid\mid p(x_a)) + \Sigma_x q(x_a)KL(q(x_b\mid x_a)\mid\mid p(x_b\mid x_a))\\
\end{split}\end{equation}
将上面两个式子合并:
$$ KL(\tilde p(x)\mid\mid p(x\theta)) = KL(\tilde p(x_c)\mid \mid p(x_c\theta)) + \Sigma_{x_a}\tilde p(x_c)KL(\tilde p(x_{-c})\mid\mid p(x_{-c}\mid x_c)) $$
从上面的式子可以看出,改变团势$\psi$并不会改变条件分布,所以对上式中第二项不会产生影响。
为了最小化第一项,和IPF的方法一样,我们将边际分布逼近观测分布。
可以将IPF解释为:保存原有的条件分布$p^{(t)}(x_{-c}\mid x_c)$,用观测数据分布取代原有的边际分布。
Feature-based Clique Potentials
当团势不能用表格表达时,或者更加一般的来说,获得团势是指数级的推测难度,必须要从有限的数据中学习指数个参数。我们可以将团变小,但是这样需要更多的独立性假设,并且改变了图模型结构。另外一种方法是不改变模型结构,使用更加一般的团势的参数。这被叫做基于特征的方法。
特征是对于一般的设定为空,对于少数特别的设定会有高低之分。每个特征函数都能变成小团势,然后将小团势乘起来就可以得到团势了。
例如,一个团势$\psi(x_1, x_2, x_3)$:
$$ \psi_c(x_a, x_2, x_3) = e^{\theta_{ing}f_{ing}}\times e^{\theta_{?ed}f_{?ed}} \times … = exp\lbrace \Sigma_{k=1}^T \theta_k f_k(c_1, c_2, c_3)\rbrace $$
每个特征都有一个权重$\theta_k$,它可以用增加或者减少团势的概率。
团上的边际分布就是一个广义指数族:
$$ p(c_1, c_2, c_3) \propto exp(\theta_{ing}f_{ing}(x_1, x_2, x_3) + \theta_{?ed}f_{?ed}(x_1, x_2, x_3) + …) $$
一般来说,特征可能是重叠的,没有限制的显示因子或者任意团变量的子集:
$$ \psi_c(x_c) = exp\lbrace \Sigma_{i\in I_c} \theta_k f_k(x_{c_i})\rbrace $$
我们可以将团势向前面一样乘起来:
$$ p(x) = \frac{1}{Z(\theta)}\psi_c (x_c) = \frac{1}{Z(\theta)}exp\lbrace \Sigma_c\Sigma_{i\in I_c} \theta_k f_k(x_{c_i})\rbrace $$
可以简化为:
$$ p(x) = \frac{1}{Z(\theta)}exp(\Sigma_i \theta_i f_i(x_{c_i})) $$
这就是指数族模型,特征值就是充分统计量。
Gerneralized Iterative Scaling - GIS
基于之前的概率函数,我们想通过一个算法求最大概率,然后有了GIS。
我们首先不是考虑直接优化目标,而是处理目标函数的下界。
\begin{equation}\begin{split} \tilde l(\theta;D) &= l(\theta;D)/N \\
&= \frac{1}{N}\Sigma_n log\ p(x_n\mid \theta) \\
&= \Sigma_x \tilde p(x)log\ p(x\mid \theta) \\
&= \Sigma_x \tilde p(x)\Sigma_i \theta_i f_i(x) - log\ Z(\theta) \\
&\geqslant \Sigma_x \tilde p(x)\Sigma_i \theta_i f_i(x) - \frac{Z(\theta)}{Z(\theta^{(t)})} - log Z(\theta^{(t)}) + 1 \\
\end{split}\end{equation}
因为对数函数有一个线性上界:$log\ Z(\theta)\leqslant \mu Z(\theta) - log\ \mu - 1$
定义:$\Delta\theta_i^{(t)} = \theta_i-\theta_i^{(t)} $
\begin{equation}\begin{split}\tilde l(\theta;D) &\geqslant \Sigma_x \tilde p(x)\Sigma_i \theta_i f_i(x) - \frac{Z(\theta)}{Z(\theta^{(t)})} - log Z(\theta^{(t)}) + 1 \\
&= \Sigma_i \theta_i \Sigma_x \tilde p(x)f_i(x) - \frac{1}{Z(\theta^{(t)})}\Sigma_x exp(\Sigma_i \theta_i^{(t)} f_i(x))exp(\Sigma_i \Delta\theta_i^{(t)}f_i(x)) - log\ Z(\theta^{(t)}) + 1\\
&= \Sigma_i \theta_i \Sigma_x \tilde p(x)f_i(x) - \Sigma_x p(x\mid \theta^{(x)})exp(\Sigma_i \Delta\theta_i^{(t)} f_i(x)) - log\ Z(\theta^{(t)}) + 1\\
\end{split}\end{equation}
假定$f_i(x) \geqslant,\Sigma_i f_i(x) = 1$,使用杰西不等式,$exp(\Sigma_i \pi_i x_i)\leqslant \Sigma_i \pi_i exp(x_i)$有:
$$ \tilde l(\theta;D) \geqslant \Sigma_i \theta_i \Sigma_x \tilde p(x)f_i(x) - \Sigma_x p(x\mid \theta^{(x)})\Sigma_i f_i(x)exp(\Delta\theta_i^{(t)}) - log\ Z(\theta^{(t)}) + 1 $$
令上面式子的右边等于$\Delta(\theta)$。
求偏导令其为零:
$$ \frac{\partial \Lambda}{\partial \theta_i} = \Sigma_x \tilde p(x)f_i(x) - exp(\Delta\theta_i^{(t)})\Sigma_x p(x\mid \theta^{(t)})f_i(x) = 0$$
$$ e^{\Delta\theta_i^{(t)}} = \frac{\Sigma_x \tilde p(x)f_i)(x)}{\Sigma_x p(x\mid \theta^{(t)})f_i(x)}= \frac{\Sigma_x \tilde p(x)f_i)(x)}{\Sigma_x p^{(t)}(x)f_i(x)}Z(\theta^{(t)}) $$
更新准则:
$$ \theta_i^{(t+1)} = \theta_i^{(t)} + \Delta\theta_i^{(t)} \Rightarrow p^{(t+1)}(x)=p^{(t)}(x)\prod_i e^{\Delta\theta_i^{(t)}} $$
\begin{equation}\begin{split} p^{(t+1)}(x) &= \frac{p^{(t)}(x)}{Z(\theta^{(t)})}\prod_i (\frac{\Sigma_x \tilde p(x)f_i)(x)}{\Sigma_x p^{(t)}(x)f_i(x)}Z(\theta^{(t)}))^{f_i(x)} \\
&= \frac{p^{(t)}(x)}{Z(\theta^{(t)})}\prod_i (\frac{\Sigma_x \tilde p(x)f_i)(x)}{\Sigma_x p^{(t)}(x)f_i(x)})^{f_i(x)}(Z(\theta^{(t)}))^{\Sigma_i f_i(x)} \\
&= p^{(t)}(x)\prod_i (\frac{\Sigma_x \tilde p(x)f_i)(x)}{\Sigma_x p^{(t)}(x)f_i(x)})^{f_i(x)} \\
\end{split}\end{equation}
总结
IPF
IPF是无向图模型求最大似然的一般方法。
- 对$\psi_c$在每个团上一个固定的等式,坐标上升。
- 在最大团边际空间上进行I-projection
- 需要势函数完全的参数化
- 必须要以最大团描述
- 对于完全可分的模型,变成一次算法
GIS
- 要以基于特征的势函数描述
- GIS是IPF的特殊形式,GIS的团势是建立在特征值配置上的。
参考文献
[1] http://www.cs.cmu.edu/~epxing/Class/10708-14/lecture.html
注:本文主要参考[1]中第8讲视频以及笔记。
