隐马尔可夫模型
隐马尔可夫模型如下图所示: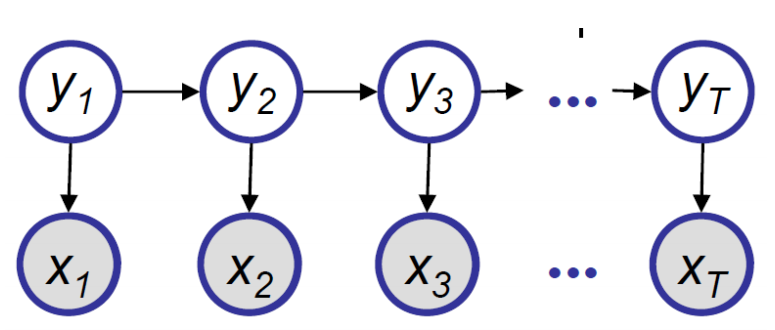
公式表达
对于隐马尔可夫模型,通常有三组参数:
$$ trasition\ probability\ matrix\ A: p(y_t^j = 1\mid y_{t-1}^i=1)=a_{i,j} $$ $$ initial\ probability: p(y_1)\sim Multinomial(\pi_1, \pi_2, …, \pi_M) $$ $$ emission\ probabilies: p(x_t\mid y_t^i)\sim Multinomial(b_{i,1}, b_{i,2}, …, b_{i,K}) $$
推断
前向算法
$$ \alpha_t^k \equiv\mu_{t-1\rightarrow}(k)=P(x_1, x_2, …, x_t, y_t^k=1) $$
$$ \alpha_t^k = p(x_t\mid y_t^k=1)\sum_i \alpha_{t-1}^ia_{i,k} $$后向算法
$$ \beta_t^k \equiv \mu_{t\leftarrow t+1}(k)=P(x_{t+1}, …, x_T\mid y_t^k=1) $$
$$ \beta_t^k = \sum_i a_{k,i}p(x_{t+1}\mid y_{t+1}^i = 1)\beta_{t+1}^i $$
对于给定观测值下的任意隐变量状态,可以同过点乘前向和后向信息得到。
$$ \gamma_t^i = p(y_t^i = 1\mid x_{1:T})\propto \alpha_t^i\beta_t^i =\sum_j \xi_t^{i,j} $$
其中有定义:
\begin{equation}\begin{split} \xi_t^{i,j} &= p(y_t^i=1,y_{t-1}^j=1, x_{1:T}) \\
&\propto \mu_{t-1\rightarrow t}(y_t^i=1)\mu_{t\leftarrow t+1}(y_{t+1}^i=1)p(x_{x+1}\mid y_{t+1})p(y_{t+1}\mid y_t) \\
&= \alpha_t^i\beta_{t+1}^j a_{i,j} p(x_{t+1}\mid y_{t+1}^i=1) \\
\end{split}\end{equation}
具体推导可以参考Youtube上徐亦达老师关于HMM的视频,主要思路就是message passing,运用一些迭代地技巧,可以先从最小的下标开始推导,这样比较容易发现规律,类似于数学归纳法。
在Matlab中可以将公式用向量表示,这样方便处理。
\begin{equation}\begin{split} &B_t(i)=p(x_t\mid y_t^i=1)\\
& A(i,j)=p(y_{t+1}^j=1\mid y_t^i=1) \\
& \alpha_t = (A^T\alpha_{t-1}).\ast B_t \\
& \beta_t = A(\beta_{t+1}.\ast B_{t+1}) \\
& \xi_t = (\alpha_t(\beta_{t+1}.\ast B_{t+1})^T).\ast A \\
& \gamma_t = \alpha_t.\ast \beta_t \\
\end{split}\end{equation}
学习
监督学习
当我们知道实际状态路径时,监督学习并不是一件困难的事情(trival),我们只需要数出转移概率和发射概率的实例就可以得到最大似然估计。
$$ a_{ij}^{ML} = \frac{\sum_n\sum_{t=2}^T y_{n,t-1}^i y_{n,t}^j}{\sum_n\sum_{t=2}^T y_{n,t-1}^i} $$
$$ b_{ik}^{ML} = \frac{\sum_n\sum_{t=2}^T y_{n,t}^i x_{n,t}^k}{\sum_n\sum_{t=2}^T y_{n,t}^i} $$
使用了伪计数的方式,可以避免零概率的出现。对于不是多项分布的情况,特别是高斯分布,我们可以利用采样的方法计算均值和方差。
无监督学习
当隐状态不可观的时候,可以使用Baum Welch算法进行处理完全对数似然函数,这一算法就是EM算法对HMM的求解方法。似然函数可以写成:
$$ l_c(\theta;x,y)=lop\ p(x,y)=log\prod_n (p(y_{n,1})\prod_{t=1}^T p(y_{n,t}\mid y_{n,t-1})\prod_{t=1}^T p(x_{n,t}\mid y_{n,t})) $$
完全对数似然期望是:
$$ \langle l_c(\theta;x,y)\rangle = \sum_n (\langle y_{n,1}^i \rangle_{p(y_{n,1}\mid x_n)}log\ \pi_i) + \sum_n\sum_{t=2}^T (\langle y_{n,t-1}^i y_{n,t}^j\rangle_{p(y_{n,t-1},y_{n,t}\mid x_n)}log\ a_{i,j}) + \sum_n\sum_{t=1}^T (x_{n,t}^k\langle y_{n,t}^i\rangle_{p(y_{n,t}\mid x_n)}log\ b_{i,k}) $$
- E步:
$$ \gamma_{n,t}^i = \langle y_{n,t}^i\rangle = p(y_{n,t}^i = 1\mid x_n) $$ $$ \xi_{n,t}^{i,j} = \langle y_{n,t-1}^i y_{n,t}^j\rangle = p(y_{n,t-1}^i=1, y_{n,t}^j=1\mid x_n) $$ - M步:
$$ \pi_i=\frac{\sum_n \gamma_{n,1}^i}{N}, a_{i,j}=\frac{\sum_n\xi_{n,t}^{i,j}} {\sum_n\sum_{t=1}^{i,j} \gamma_{n,t}^i}, b_{ik}=\frac{\sum_N\sum_{t=1}^T \gamma_{n,t}^i x_{n,t}^k} {\sum_n\sum_{t=1}^{T-1}\gamma_{n,t}^i} $$
HMM的缺点
HMM的缺点也是HMM的最要特征,就是每个观测值只与一个隐状态相关,与其他状态都无关。另外就是预测目标函数与学习目标函数不一致,HMM学习状态和观测值的联合概率$P(Y,X)$,但是我们的预测要求是需要条件概率$P(Y\mid X)$,通过这样的考虑,有了一个新的模型MEMM。
MEMM
模型结构
MEMM结构如下图所示: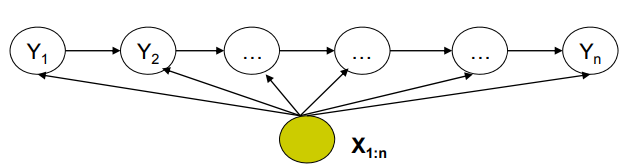
MEMM的主要特点是,模型中的每个状态都与所有的观测值相关,同时模型是一个判别模型。
$$ P(y_{1:n}\mid x_{1:n}) = \prod_{i=1}^{n} P(y_i\mid y_{i-1},x_{1:n}) = \prod_{i=1}^n \frac{exp(W^T f(y_i,y_{i-1}, x_{1:n}))}{Z(y_{i-1}, x_{1:n})} $$
缺点
MEMM存在着标注偏置的问题(label bias preblem),主要是因为状态转移的路径多少的问题,MEMM中的状态倾向于转移到转移状态路径少的状态,因为转移路径少的状态总能提供较大的转移概率。
CRF
一个比较好的方法解决上面的问题就是改变原来的概率转移的方式,用势函数取代概率来表征局部的信息。
模型结构
CRF结构如下图所示: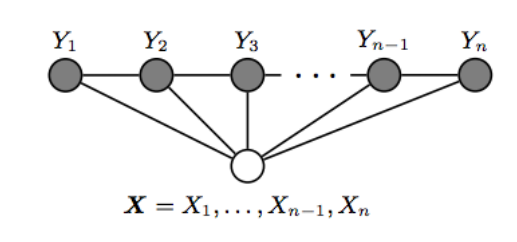
\begin{equation}\begin{split} P(Y\mid X) &= \frac{1}{Z(X)}\prod_{i=1}^n \phi(y_i,y_{i-1},X) \\
&= \frac{1}{Z(X, \lambda, \mu)}exp(\sum_{i=1}^T(\sum_k \lambda_k f_k(y_i, y_{i-1}, X) + \sum_l \mu_l g_l(y_i, X))) \\
\end{split}\end{equation}
其中,$Z(X,\lambda, \mu)=\sum_y exp(\sum_{i=1}(\sum_k \lambda_k f_k(y_i, y_{i-1}, X) + \sum_l \mu_l g_l (y_i, X))) $,可以看出其中的正规因子是全局的,并不是局部的,这样就保证了对局部信息的处理具有全局一致性。
推断
所谓的推断问题就是在CRF给定参数$\lambda$和$\mu$,我们可以找到$y^{\ast}$使得$P(y\mid x)$最大。
$$ y^{\ast} = argmax_y exp(\sum_{i=1}^n (\sum_k \lambda_k f_k (y_i, y_{i-1}, X) + \sum_l \mu_l g_l (y_i, X))) $$
因为Z与y无关,最大值与y无关。为了解决优化问题,我们可以使用最大积算法在CRF上,这样类似了Viteerbi算法在HMM上的应用。
学习
尽管整个图都是可观的,CRF的学习问题仍然是比较难于解决的。原因是学习中需要进行推断。给定训练集$\lbrace x_d, y_d\rbrace_{d=1}^N$,寻找到最优的$\lambda^{\ast}$和$\mu^{\ast}$。
\begin{equation}\begin{split} \lambda^{\ast}, \mu^{\ast} &= argmax_{\lambda, \mu}\prod_{d=1}^N P(y_d\mid x_d, \lambda, \mu) \\
&= argmax_{\lambda, \mu}\prod_{d=1}^N \frac{1}{Z(x_d, \lambda, \mu)}exp(\sum_{i=1}^n (\lambda^T f(y_{d, i} y_{d, i-1}, x_d) + \mu^T g(y_{d,i}, x_d))) \\
&= argmax_{\lambda, \mu}\sum_{d=1}^T (\sum_{i=1}^n(\lambda^T f(y_{d,i}, y_{d, i-1}) + \mu^T g(y_{d, i}, x_d)) - log\ Z(x_d, \lambda, \mu)) \\
\end{split}\end{equation}
对$\lambda$求偏导:
$$ \Delta_{\lambda}L(\lambda, \mu) = \sum_{d=1}^N(\sum_{i=1}^n f(y_{d, i}, y_{d, i-1}, x_d) - \sum_y (P(y\mid x_d) \sum_{i=1}^n f(y_{d, i}, y_{d, i-1}, x_d))) $$
从上式中可以看出第一项是特征值,第二项是特征值的期望,另外对数判分函数以指数族的形式呈现时,其梯度是特征值的期望。
解决上面的式子需要处理指数级数量的数据求和,我们可以利用message passing算法来计算对势,这样得到一个闭环的形式。
\begin{equation}\begin{split} \sum_y (P(y\mid x_d)\sum_{i=1}^n f(y_i, y_{i-1}, x_d)) &= \sum_{i=1}^n(\sum_y f(y_i, y_{i-1}, x_d) P(y\mid x_d)) \\
&= \sum_{i=1}^n(\sum_{y_i, y_{i-1}} f(y_i, y_{i-1}, x_d) P(y_i, y_{i-1}\mid x_d)) \\
\end{split}\end{equation}
这样意味着,学习过程中包含有推断过程,通过message passing算法,学习过程只需要多项式时间久可以完成。
下面使用校准势来计算特征期望:
\begin{equation}\begin{split} \Delta_{\lambda}L(\lambda, \mu) &= \sum_{d=1}^N(\sum_{i=1}^n f(y_{d, i}, y_{d, i-1}, x_d) - \sum_y (P(y\mid x_d) \sum_{i=1}^n f(y_{d, i}, y_{d, i-1}, x_d))) \\
&= \sum_{d=1}^N(\sum_{i=1}^n f(y_{d,i}, y_{d,i-1】, x_d} - \sum_{y_i, y_{i-1}}\alpha’(y_i, y_{i-1}) f(y_d, y_{d, i-1}, x_d))) \\
\end{split}\end{equation}
其中$\alpha’(y_i, y_{i-1}, x_d) = P(y_i, y_{i-1}\mid x_d)$。我们可以使用梯度上升法学习参数。
$$ \lambda^{(t+1)} = \lambda^{(t)} + \eta\Delta_{\lambda}L(\lambda^{(t)}, \mu^{(t)}) $$ $$ \mu^{(t+1)} = \mu^{(t)} + \eta\Delta_{\mu}L(\lambda^{(t)}, \mu^{(t)}) $$
在实际中,我们会加入正则项来提高参数的泛化能力。
$$ \lambda^{\ast}, \mu^{\ast} = argmax_{\lambda, \mu}\sum_{d=1}^N log\ P(y_d\mid x_d, \lambda, \mu) - \frac{1}{2\sigma^2} (\lambda^T \lambda + \mu^T\mu) $$
第二项叫做高斯先验,因为我们想让$\lambda^{\ast},\mu^{\ast}$趋近于0,这样可以减少特征值的数量。第二项也能叫做拉普拉斯先验,在条件概率中,我们不想看到零概率出现,因为零概率是病态的。梯度上升法收敛速度较慢,以使用共轭梯度法和拟牛顿法来加快速度。
从经验的表现来看,CRF比HMM和MEMM有所提升,特别是当非局部的影响明显时。虽然提升不够明显,但是CRF为一系列的问题的解决提供了很好的范例。CRF的另一优点是能够让使用者灵活的自己设计随机特征。
总结
- EM算法适应于处理存在隐变量的最大似然估计问题。
- GMM和HMM被用于对静态和动态混合模型建模。
- 实现HMM主要需要处理的问题是,学习,推断和最大似然。推断可以通过前向和后向算法(变量去除)实现;最大似然问题可以通过Viterbi算法(最大积)实现;学习问题可以通过直接最大似然后者EM算法解决。
- HMM具有十分强的马尔科夫性。HMM只能获得局部的关系,对于HMM的扩展MEMM,MEMM可以获得状态和全部可观序列之间的显性关系。但是,MEMM存在着标注偏置的问题。
- CRF是部分有向的模型,其中转态之间是无向的,CRF使用全局的正规项克服了MEMM的标注偏置的问题。对于线性链式CRF,精确推断并不是困难的。推断问题可以通过最大积算法通过junction tree解决。学习问题可以通过梯度上升来解决最大似然。
- 具有任意图结构的CRF,精确推断就是比较困难的事情,这时就需要近似推断了,比如:采样,变分推断,loopy belief propagation。
参考文献
[1] http://www.cs.cmu.edu/~epxing/Class/10708-14/lecture.html
[2] Wallach H M. Conditional random fields: An introduction[J]. Technical Reports (CIS), 2004: 22.
注:本文主要参考[1]中第12讲视频以及笔记。另外,本文中公式的和全部采用\sum,本文之前使用的都是\Sigma,后面也会使用\sum。
