简介
不同于最大似然估计对于贝叶斯网的估计,有向图中,网络结构通常是已知的,我们需要做的是将参数学习出来或者是对于变量进行推断。无向图中则并不是这样,无向图中,很多模型的结构并不是完全清楚的,需要我们队模型结构进行推断。
高斯图模型
高斯图模型是马尔科夫随机场的成对形式,同样也是满足高斯正态分布:
$$ p(x\mid \mu, \Sigma) = \frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}}exp[-\frac{1}{2}(x-\mu)^T \Sigma^{-T}(x-\mu)] $$
其中$\mu$是均值,$\Sigma$是协方差矩阵。令$\mu=0$和精度矩阵为$Q=\Sigma^{-1}$,有:
$$ p(x_1, x_2, …, x_p\mid \mu=0, Q) = \frac{|Q|^{1/2}}{(2\pi)^{n/2}}exp[-\frac{1}{2}\sum_i q_{ii}(x_i)^2 - \sum_{i<j}q_{ij}x_ix_j] $$
这就是条件随机场,定义于成对边和节点上。
协方差矩阵与精度矩阵
协方差矩阵有一个重要的性质是:当$\Sigma_{i,j}=0$有$x_i\perp x_j$;逆协方差矩阵(精度矩阵)的对应的性质为:当$\Sigma_{i,j}^{-1}=0$时$x_i\perp x_j\mid x_{-ij}$。
利用LASSO进行网络学习
LASSO回归
对于网络结构的学习,我们通常是假设网络是稀疏的。LASSO回归可以用于网络的近邻选择,去除不必要的节点之间的连接。
$$\hat{\beta_1} = argmin_{\beta_1}\parallel Y - X\beta_1\parallel^2 + \lambda\parallel\beta_1\parallel_1$$
其中,$\beta_1$是节点1的参数,Y是是对节点1的独立观测值。
具体过程如图所示: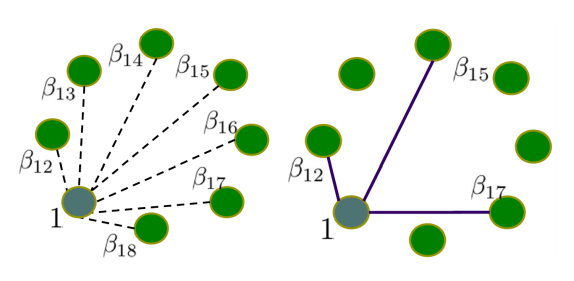
理论条件
- Dependency Condition: Relevant Covariates are not overly dependent
- Incoherence Condition: Large number of irrelevant covariates can’t be too correlated with relevant covariates
- Strong concentration bounds: Sample quantities coverge to expected values quickly
时变网络
KELLER: Kernel Weightd $L_1$-regularized logistic Regression
对时变网络的结构进行估计,可以采用KELLER的方法解决:
$$ \hat{\theta_i^t} = argmain_{\theta_i^t}l_w(\theta_i^t) + \lambda_1\parallel\theta_t^t \parallel_1 $$
其中$l_w(\theta_i^t) = \sum_{t’=1}^T w(x^{t’}; x^t)log\ P(x_i^{t’}\mid x_{-i} x^{t’}, \theta_i^t)$。权值$w(x^{t’}; x^t)$决定了在时间$t’$和$t$之间的关系,我们可以将其建模为一个分布(如下图)。
给定时间$t^{\ast}$,权值可以写成:
$$ w_t(t^{\ast}) = \frac{K_{h_n}(t-t^{\ast})}{\sigma_{t’\in T^n} K_{h_n}(t’-t^{\ast})} $$
对于一些平滑的核$K_{h_n}$。
TESLA: Temporally Smoothed $L_1$-regularized logistic regression
TESLA对于一个节点的参数优化是基于所有的时间步的:
$$ \hat{\theta_i^T}, …, \hat{\theta_i^T} = argmin\sum_{i=1}^T l_{avg}(\theta_i^t) + \lambda_1 \sum_{t=1}^T \parallel\theta_{-1}^t \parallel_1 + \lambda_2\sum_{t=1}^T \parallel \theta_i^t - \theta_i^{t-1} \parallel $$
其中,$l_{avg}(\theta_i^t) = \frac{1}{N^t}\sum_{d=1}^{N^t} log\ P(x_{d,i}^t\mid x_{d, -i}^t, \theta_i^t) $是条件对数似然。不同于KELLER,当节点数达到5000时,这里我们不需要平滑Kernels,这里可以接受突变。
