VGGNet模型结构
VGGNet是牛津大学视觉组(Visual Geometry Group)和Google DeepMind公司研究员共同研究出的深度卷积神经网络。VGGNet使用的比较小的卷积核(3x3)以及2x2的最大池化层,通过增加层数增强非线性性能,同时相较于7x7的卷积核而言,减少了参数。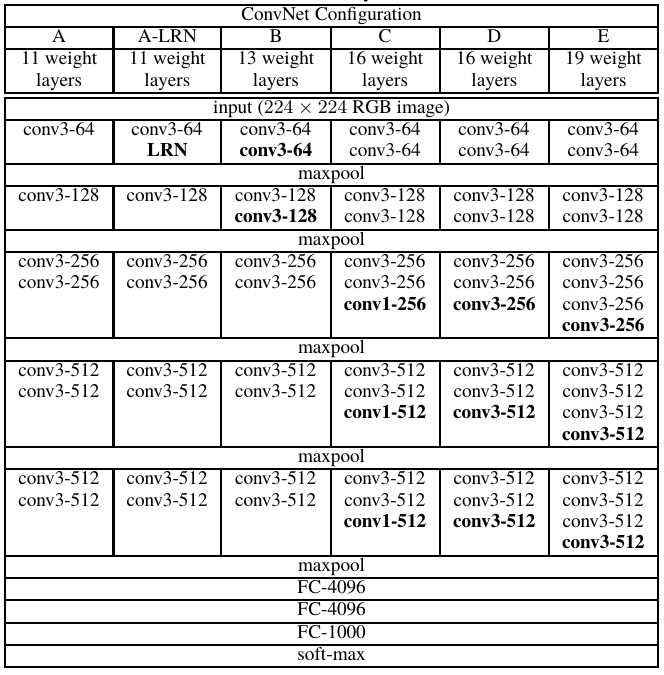
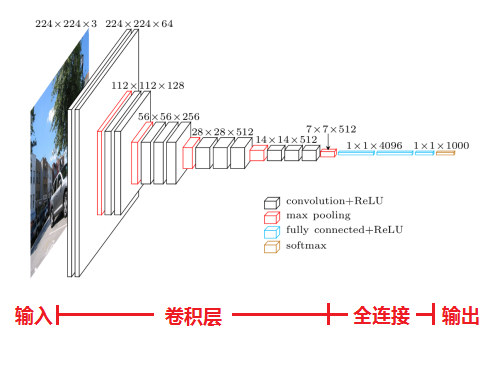
VGG16模型处理过程
以上面图的D为例,下面简要的阐述VGGNet模型的处理过程。
- 输入224x224x3的图片,经过64个3x3的卷积核做两次卷积+ReLU,变成224x224x64。
- 做MaxPool,池化尺寸为2x2,步长(stride)为2。
- 经过128个3x3的卷积核做两次卷积+ReLU,尺寸变为112x112x128。
- MaxPool,尺寸变为56x56x128。
- 256个3x3的卷积核做三次卷积+ReLU,尺寸变为56x56x256。
- MaxPool,尺寸变为28x28x256。
- 经512个3x3的卷积核做三次卷积+ReLU,尺寸变为28x28x512。
- MaxPool,尺寸变为14x14x512。
- 经512个3x3的卷积核做三次卷积+ReLU,尺寸变为14x14x512。
- MaxPool,尺寸变为7x7x512。
- 与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)。
- 通过softmax输出1000个预测结果。

利用VGG19实现火灾分类
主要参考[1]中的代码,另外我将自己跑出的结果贴在了我的github上,具体地址为[4]。
参考文献
[1] http://www.cnblogs.com/vipyoumay/p/7884472.html
[2] https://my.oschina.net/u/876354/blog/1634322
[3] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[4] https://github.com/hjyai94/VGG
