最近写论文写不动,然后又不知道干点啥来荒废时间,正好看到了一本挺有意思的算法书《我的第一本算法书》,准备读一读,结合一些开源的程序,学习一下,并实现一下。本文的主要内容来自于《我的第一本算法书》和维基百科。
算法的时间复杂度
算法的时间复杂度通常用 $O$ 符号来表示,它的意思是忽略重要项以外的内容,比如说 $O(n^2)$ 表示算法的运行时间最长为 $n^2$ 的常数倍。
- 如果链表中的数据量为 $n$,我们从链表头部线性查找,如果目标在链表最后,需要的时间为 $o(n)$。链表中添加数据只需要更改两个指针的指向,所以耗费的时间与 $n$ 无关。如果到达了添加(删除)数据的位置,那么添加(删除)只需要 $O(1)$ 的时间。
- 数组与链表不同,数据是通过下表确定内存地址的,所以访问 $n$ 个数据的某个数据仅为恒定的 $O(1)$ 时间。若向数组中添加数据,则需要将目标位置的数据之后的数据一个个移开,如果在头部添加数据则需要 $O(n)$ 时间,删除同理。
- 在哈希表中,可以采用哈希函数快速访问到数组中的目标数据,如果发生哈希冲突,我们就使用链表进行存储。
- 在堆中,假设有 $n$ 个节点,根据堆的特点我们可以知道堆的高度为 $log_2\ n$ (类似于等比数列求和),那么对堆进行排序时间复杂度为 $O(log\ n)$。
- 二叉搜索树的比较次数取决于树的高度,如果节点为 $n$,树的的形状又较为均衡的话,比较的大小和移动的次数最多为 $log_2\ n$, 因此时间复杂度为 $O(log\ n)$。
排序
所谓排序就是讲数据按照升序的方式调整顺寻,下面将介绍几种常见的排序算法。
冒泡排序
冒泡算法重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。冒泡排序对 $n$ 个数据的排序的时间复杂度 $O(n^2)$ 。
1 | def bubble_sorted(iterable): |
选择排序
选择排序是一种简单直接的排序算法。它的工作原理如下:首先找到未排序列中最小的元素,存放在
排序序列的其实位置,然后再从剩余未排序元素中寻找最小元素,然后放到一排序序列的末尾,一次类推,知道所有元素排序完毕,如下图所示。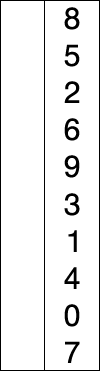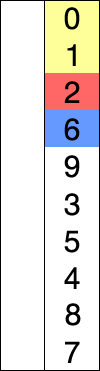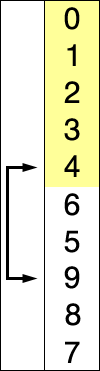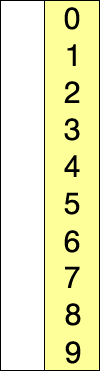
1 | def selection_sort(arr): |
插入排序
插入排序的工作原理是通过构建有序序列,对于为排序数据,在一排序序列中从后向前扫描,找到相应位置并插入,如下图所示。算法的时间复杂度为 $O(n^2)$。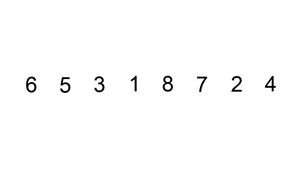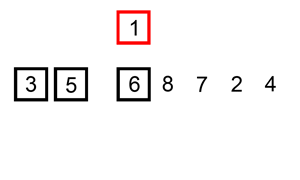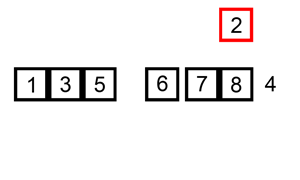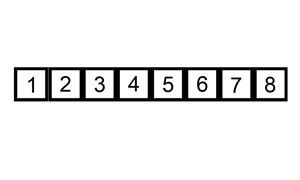
1 | def insertion_sort(lst): |
堆排序
堆排序是指利用对这种数据结构设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。堆排序的顺序是将元素进行重排,以匹配堆的条件。下图中排序过程之前简单地绘出了堆树的结构。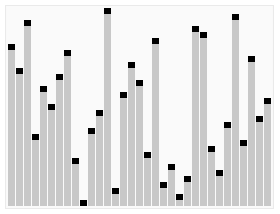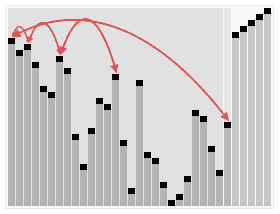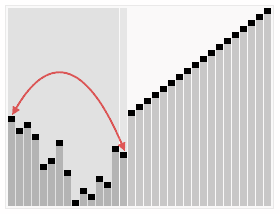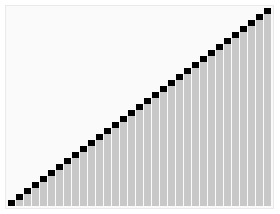
1 | #!/usr/bin/env python |
归并排序
归并排序会将序列分成长度相同的来那个子序列,当无法继续往下分时(也就是每个子序列只有一个数据时),就对子序列归并。归并指的是把来那个排好序的子序列合并成一个有序序列。该操作会一直进行,知道所有子序列都归并为一个整体为止。归并排序的算法时间复杂度为 $O(nlog\ n)$。
1 | # Recursively implementation of Merge Sort |
快速排序
快速排序是在数列中挑选一个元素作为基准(pivot),然后将数列按照“比基准小的数”和“比基准大的数”分为两类,然后进行使用快速排序进行递归排序“比基准小的数”和比“基准大的数”。快速排序的算法平均时间复杂度为 $O(nlog\ n)$,因为其内部循环可以再大部分框架上很有效率的完成,所以称之为快速算法。
1 | def quick_sort(lst): |
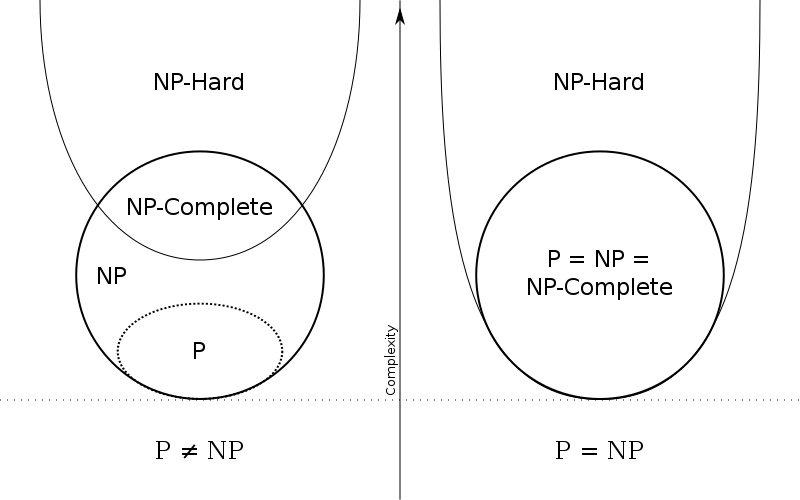
P问题,NP问题,NP Complete问题,NP困难问题
这部分是偶然看到的,和这里关系不大。
P问题是指在多项式时间内可以解决的问题;NP问题是指在多项式时间内可以判断的问题;NP Complete是指在多项式时间内判断,不能在多项式时间内解决的问题。NP困难问题是指如果所有的NP问题都可以在多项式时间内归约到某个问题。
具体上面问题的分布情况可以参照下面的图,目前普遍认为 $P \neq NP$,如果$P = NP$,那么这个世界确实会很不一样,人人都能成为莫扎特系列。