自回归语言生成
我们先回顾一下自回归 (auto-regressive) 语言生成的过程。自回归语言生成假设每个词语序列的概率都可以分解为一系列条件词语概率的乘积:
$$
P\left(w_{1: T} \mid W_0\right)=\prod_{t=1}^T P\left(w_t \mid w_{1: t-1}, W_0\right), \quad w_{1: 0}=\varnothing
$$
这样就可以迭代地基于上下文 $W_0$ 以及已经生成的词语序列 $w_{1: t-1}$ 来预测序列中的下一个词 $w_t$ ,因此被称为自回归 (auto-regressive)。生成序列的长度 $T$ 通常不是预先确定的,而是当生成出休止符(EOS token)时结束迭代。
Transformers 库中所有的生成模型都提供了用于自回归生成的 generate() 函数,例如 GPT2、XLNet、OpenAi-GPT、CTRL、TransfoXL、XLM、Bart、T5 等等。
下面我们将介绍目前常用的四种解码方式:
- 贪心搜索 (Greedy Search)
- 柱搜索 (Beam search)
- Top-K 采样 (Top-K sampling)
- Top-p 采样 (Top-p sampling)。
为了方便,我们将统一使用 GPT-2 模型来进行展示。
1 | from transformers import AutoTokenizer, AutoModelForCausalLM |
贪心搜索
贪心搜索 (Greedy Search) 在每轮迭代时,即在时间步 $t$ ,简单地选择概率最高的下一个词作为当前词,即 $w_t=\operatorname{argmax}w P\left(w \mid w{1: t-1}\right)$ 。下图展示了一个贪心搜索的例子:
![[Pasted image 20231121141847.png|500]]
可以看到,从起始词语“The”开始,贪心算法不断地选择概率最高的下一个词直至结束,最后生成词语序列 (“The” “nice” “woman”),其整体概率为 $0.5×0.4=0.2$。
下面我们使用 GPT-2 模型结合贪心算法来为上下文 (“I”, “enjoy”, “walking”, “with”, “my”, “cute”, “dog”) 生成后续序列:
1 | # encode context the generation is conditioned on |
1 | Output: |
模型成功地生成了一个短文本,但是它似乎开始不停地重复。这是一个语言生成中常见的问题,特别是在贪心搜索和柱搜索中经常会出现。
贪心搜索最大的问题是由于每次都只选择当前概率最大的词,相当于是区部最优解,因此生成的序列往往并不是全局最优的。 例如在上图中,词语序列 (“The”, “dog”, “has”) 的概率是 $0.4×0.9=0.36$,而这个序列无法通过贪心算法得到。
柱搜索
柱搜索 (Beam search) 在每个时间步都保留 num_beams 个最可能的词,最终选择整体概率最大的序列作为结果。下图展示了一个 num_beams=2 的例子:
![[Pasted image 20231121144829.png|500]]
可以看到,在第一个时间步,柱搜索同时保留了概率最大的前 2 个序列:概率为 0.4 的 (”The“, ”dog“) 和概率为 0.5 的 (”The“, ”nice“);在第二个时间步,柱搜索通过计算继续保留概率最大的前 2 个序列:概率为 0.4×0.9=0.36 的 (”The“, ”dog“, ”has“) 和概率为 0.5×0.4=0.2 的 (”The“, ”nice“, ”woman“);最终选择概率最大的序列 (”The“, ”dog“, ”has“) 作为结果。
柱搜索虽然通过在每个时间步保留多个分支来缓解贪心算法局部最优解的问题,但是它依然不能保证找到全局最优解。
下面我们同样运用 GPT-2 模型结合柱搜索来生成文本,只需要设置参数 num_beams > 1 以及 early_stopping=True,这样只要所有柱搜索保留的分支都到达休止符 EOS token,生成过程就结束。
1 | # activate beam search and early_stopping |
1 | Output: |
虽然柱搜索得到的序列更加流畅,但是输出中依然出现了重复片段。最简单的解决方法是引入 n-grams 惩罚,其在每个时间步都手工将那些会产生重复 n-gram 片段的词的概率设为 0。例如,我们额外设置参数 no_repeat_ngram_size=2 就能使生成序列中不会出现重复的 2-gram 片段:
1 | # set no_repeat_ngram_size to 2 |
1 | Output: |
不过 n-grams 惩罚虽然能够缓解“重复”问题,却也要谨慎使用。例如对于一篇关于”New York“文章就不能使用 2-gram 惩罚,否则”New York“在全文中就只能出现一次了。
柱搜索会在每个时间步都保留当前概率最高的前 num_beams 个序列,因此我们还可以通过设置参数 num_return_sequences(<= num_beams)来返回概率靠前的多个序列:
1 | # set return_num_sequences > 1 |
1 | Output: |
由于柱大小只被设为 5,因此最终获得的 3 个序列看上去非常接近。
有趣的是,人类语言似乎并不遵循下一个词是最高概率的分布,换句话说,真实的人类语言具有高度的随机性,是不可预测的。下图展示了人类语言与柱搜索在每个时间步词语概率的对比:
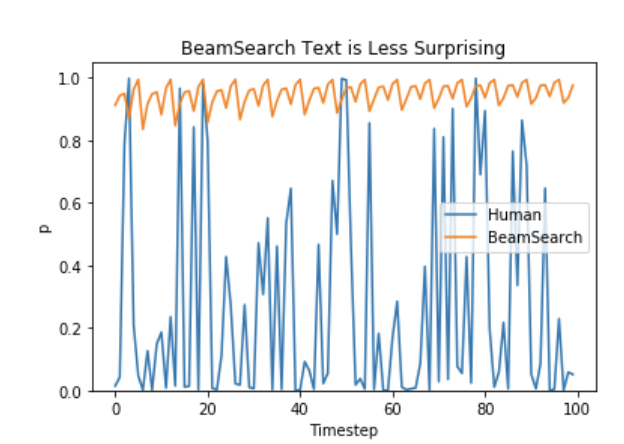
因此,柱搜索更适用于机器翻译或摘要等生成序列长度大致可预测的任务,而在对话生成、故事生成等开放式文本生成任务 (open-ended generation) 上表现不佳。虽然通过 n-gram 或者其他惩罚项可以缓解“重复”问题,但是如何控制”不重复”和“重复”之间的平衡又非常困难。
所以,对于开放式文本生成任务,我们需要引入更多的随机性——这就是采样方法。
随机采样
采样 (sampling) 最基本的形式就是从当前上下文的条件概率分布中随机地选择一个词作为下一个词,即:
$$
w_t \sim P\left(w \mid w_{1: t-1}\right)
$$
对于前面图中的例子,一个基于采样的生成过程可能为(采样生成的结果不是唯一的):
![[Pasted image 20231121150710.png]]
这里“car”是从条件概率分布 $P(w \mid$ “The” $)$ 中采样得到,而“drives”是从分布 $P(w \mid$ “The”, “car” ) 中采样得到。
在 Transformers 库中,我们只需要在 generate() 中设置 do_sample=True 并且令 top_k=0 禁用 Top- $K$ 采样就可以实现随机采样:
1 | # set seed to reproduce results. Feel free to change the seed though to get different results |
1 | Output: |
看上去还不错,但是细读的话会发现不是很连贯,这也是采样生成文本的通病:模型经常会生成前后不连贯的片段。一种解决方式是通过降低 softmax 的温度 (temperature) 使得分布 $P\left(w \mid w_{1: t-1}\right)$ 更尖锐,即进一步增加高概率词出现的可能性和降低低概率词出现的可能性。例如对上面的例子应用降温:
![[Pasted image 20231121151133.png]]
这样在第一个时间步,条件概率变得更加尖锐,几乎不可能会选择到“car”。我们只需要在 generate() 中设置 temperature 来就可以实现对分布的降温:
1 | # set seed to reproduce results. Feel free to change the seed though to get different results |
1 | Output: |
可以看到生成的文本更加连贯了。降温操作实际上是在减少分布的随机性,当我们把 temperature 设为 0 时就等同于贪心解码。
Top-K 采样
类似于柱搜索,Top- $K$ 采样在每个时间步都保留最可能的 $K$ 个词,然后在这 $K$ 个词上重新分配概率质量。 例如我们对上面的示例进行 Top- $K$ 采样,这里设置 $K=6$ 在每个时间步都将采样池控制在 6 个词。
![[Pasted image 20231121151332.png]]
可以看到,6 个最可能的词(记为 $V_{\mathrm{top}-\mathrm{K}}$ )虽然仅包含第一个时间步中整体概率质量的大约 $\frac{2}{3}$ ,但是几乎包含了第二个时间步中所有的概率质量。尽管如此,它还是成功地消除了第二步中那些奇怪的候选词(例如”not”、”the”、”small”、”told” )。
下面我们通过在 generate() 中设置 top_k=10 来进行 Top-K 采样:
1 | # set seed to reproduce results. Feel free to change the seed though to get different results |
1 | Output: |
Top-K 采样的一个问题是它无法动态调整每个时间步从概率分布 $P$ 中过滤出来的单词数量,这会导致有些词可能是从非常尖锐的分布(上图中右侧)中采样的,而其他单词则可能是从平坦的分布(上图中左侧)中采样的,从而无法保证生成序列整体的质量。
Top-p (nucleus) 采样
Top-p 对 Top-K 进行了改进,每次只从累积概率超过 $p$ 的最小的可能词集中进行选择,然后在这组词语中重新分配概率质量。 这样,每个时间步的词语集合的大小就可以根据下一个词的条件概率分布动态增加和减少。下图展示了一个 Top-p 采样的例子:
![[Pasted image 20231121152000.png]]
这里我们设置 $p=0.92$ ,$Top-p$采样在每个时间步会在整体概率质量超过 $92 %$ 的最小单词集合(定义为 $V_{\text {top-p }}$ )中进行选择。上图左边的例子中,Top- $p$ 采样出了 9 个最可能的词语,而在右边的例子中,只选了 3 个最可能的词,整体概率质量就已经超过了 $92 %$ 。可以看到,当下一个词难以预测时(例如 $P(w \mid “The”)$ ),Top-p 采样会保留很多可能的词,而当下一个词相对容易预测时(例如 $P(w \mid “The”, “car”)$),Top-p 就只会保留很少的词。
我们只需要在 generate () 中设置 $\theta<t o p _p<1$ 就可以激活 Top-p 采样了:
1 | # set seed to reproduce results. Feel free to change the seed though to get different results |
1 | Output: |
虽然理论上 Top-p 采样比 Top-K 采样更灵活,但是两者在实际应用中都被广泛采用,Top-p 甚至可以与 Top-K 共同工作,这可以在排除低概率词的同时还允许进行一些动态选择。
最后,与贪心搜索类似,为了获得多个独立采样的结果,我们设置 num_return_sequences > 1,并且同时结合 Top-p 和 Top-K 采样:
